Deploy Gathr Using Ansible Playbook
Deploy Gathr and its essential components, such as Elasticsearch, RabbitMQ, Zookeeper, PostgreSQL, Spark Standalone, and HDFS/YARN, using Ansible Playbook.
Prerequisites
Ensure the following prerequisites to successfully set up and deploy these components.
1. Ansible Server
Ansible should be installed on the server from where you will run the playbook.
Password less SSH must be enabled from the Ansible server to the Gathr and HAProxy servers.
2. System Requirements for Gathr
Operating System: RHEL 9 / OEL 9 is required.
High Availability (HA) Deployment: HAProxy and Gathr must run on separate machines.
Hardware Specifications:
Service CPU RAM Optional Zookeeper 2 CPU 4 GB No Postgres 2 CPU 4 GB No Gathr 8 CPU 32 GB No Elasticsearch 2 CPU 4 GB Yes RabbitMQ 1 CPU 2 GB Yes Spark Standalone Custom Custom Yes HDFS & YARN Custom Custom Yes Software Dependencies:
Python 3.9 must be available (preinstalled on RHEL 9 / OEL 9).
SELinux must be disabled on the servers.
3. Shared Location
Create a shared path accessible by both Gathr and Spark/YARN nodes.
For Gathr Analytics Deployment, ensure the same path is available on Analytics Nodes.
4. HAProxy Server
Ensure the HAProxy Server is running with SSL for Analytics Deployment. Non-SSL is acceptable if not using Analytics.
A valid .pem file is required for SSL on HAProxy.
5. Port Availability
Ensure the following ports are available on the servers where the services are deployed:
| Service | Ports (Default) | Optional | Notes |
|---|---|---|---|
| Zookeeper | 2181, 2888, 3888, 8081 | No | Ports can be modified before running the playbook. |
| Postgres | 5432 | No | Port can be modified before running the playbook. |
| Gathr | 8090, 9595 | No | Ports can be modified before running the playbook. |
| Elasticsearch | 9200, 9300 | Yes | Ports can be modified before running the playbook. |
| RabbitMQ | 5672, 15672 | Yes | Ports can be modified before running the playbook. |
| Spark Standalone | 7077, 8080, 8081, 6066, 18080 | Yes | Ports can be modified before running the playbook. |
| HDFS & YARN (Non-HA) | 8020, 9870, 9864, 9866, 9867, 8141, 8088, 8030, 8025, 8050, 8042, 8040, 19888, 10020, 10033 | Yes | Ports are non-configurable. |
| HDFS & YARN (HA) | 8485, 8480, 8020, 50070, 8019, 9866, 9867, 50075, 8141, 8088, 8030, 8025, 8050, 8042, 8040, 19888, 10020, 10033 | Yes | Ports are non-configurable. |
6. Application User and Group
- Create an application user on the servers with password-based authentication.
7. (Optional) OpenAI API Key Requirement
An OpenAI API key is necessary for the Gathr IQ features.
Internet access is needed for this feature to work.
8. (Optional) Data Intelligence
Shared Storage for Logs and Data (Optional for single-node setups)
- Configure a shared mount (EFS/NFS) on the Docker-installed machine for Data Intelligence logs and data.
Logstash Configuration
Install and configure Logstash (version 6.8.23) on the chosen node, ensuring it is seamlessly integrated with the designated Elasticsearch instance.
Additionally, configure Logstash to process logs from the DI log directory for efficient log management.
Logstash service should run on the same node where DI application logs are stored.
Access Control for Gathr User
- Ensure Gathr users have access to Data Intelligence Docker logs.
- Set up ACL permissions if necessary.
Load Balancer for Multi-DI Deployments (Optional for single node DI Docker)
- Configure a private load balancer for multi-DI Docker deployments.
AWS CloudWatch Integration (Applicable for AWS Deployments Only)
- Configure AWS CloudWatch and Agent for log monitoring.
9. (Optional) For MLflow
Ensure a private docker registry is available for MLflow images.
Kubernetes Cluster should be operational.
Artifact Storage Configuration:
MLFlow generates artifacts when a model is registered, which can be stored in either S3 or NFS.
If using S3 or Ceph for artifact storage, ensure you have the following credentials:
S3 Access Key
S3 Secret Key
S3 Endpoint URL
If using NFS, make sure you have the PVC (Persistent Volume Claim) name that the Gathr pod is using to share the path between the Gathr and MLFlow pods.
(Optional) Private Docker Registry Access should be available to pull from the private docker repository.
Steps to Install Gathr and Supported Components
Download the playbook bundle shared by the Gathr team.
Extract the bundle using the following command:
tar -xzf GathrBundle.tar.gzNavigate to the Playbook Path:
cd /path/to/playbookOpen the
saxconfig_parametersfile with a text editor. Refer comments in the file to modify the configuration properties as required for your environment.Execute the following command to reload the Ansible variables:
./config.shExecute the playbook with the following command:
export ANSIBLE_DISPLAY_SKIPPED_HOSTS=false ansible-playbook -i hosts installGathrStack.yml -vv
Post Deployment Validation
Navigate to the Gathr UI using the URL
http://<GATHR_HOST>:8090/. When the interface loads, a license agreement page will display: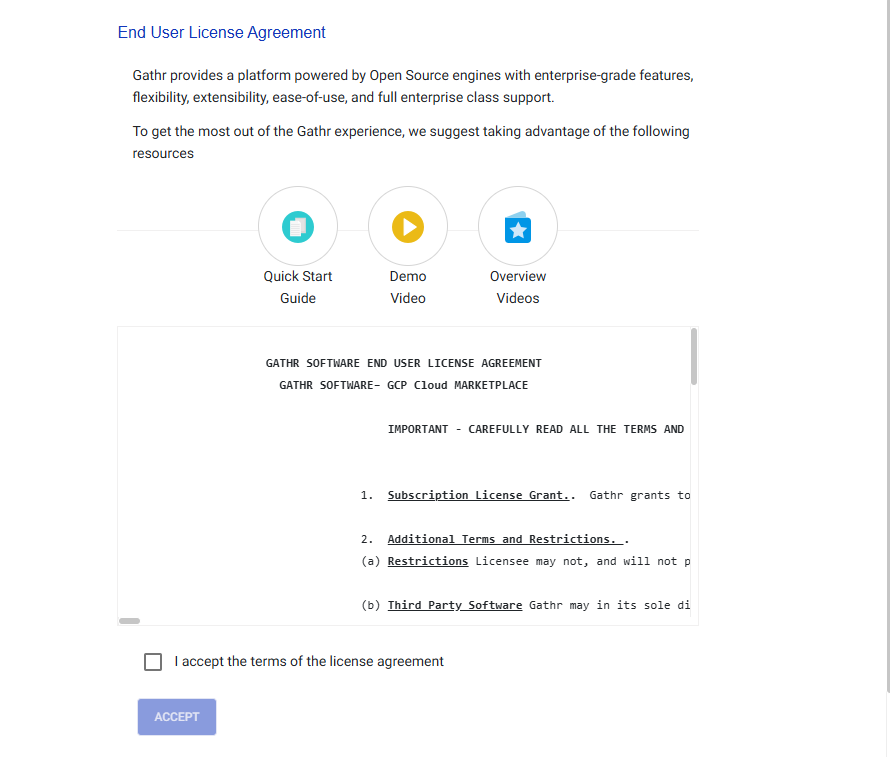
Check the “I accept” box and click the “Accept” button.
The Upload License page will then be visible:
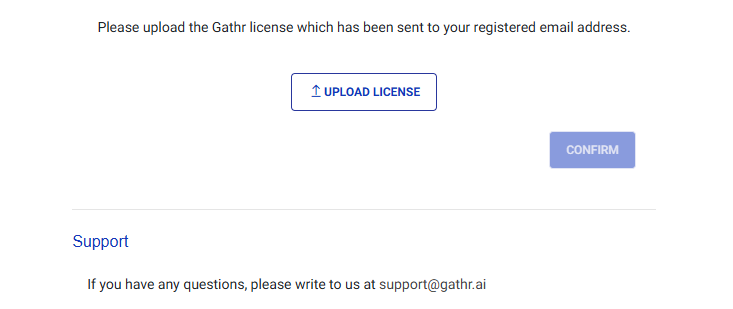
Upload your valid Gathr license and click “Confirm”.
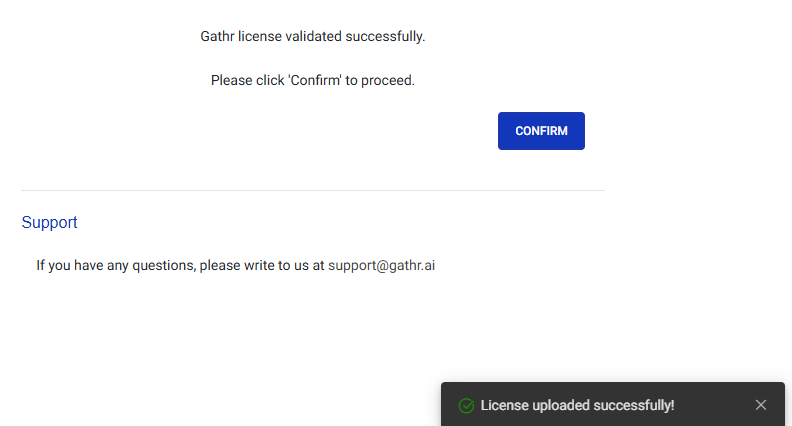
Proceed by clicking “Continue” on the welcome page:
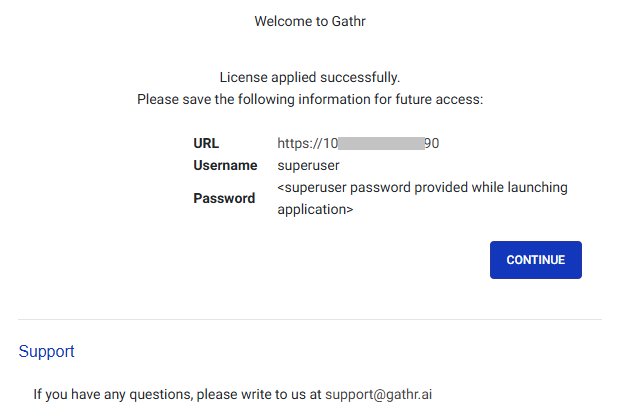
This will lead you to the Login Page:
Log in using the default superuser credentials:
Email: super@mailinator.com
Password: superuser
The deployment of Gathr is now complete.
If you have any feedback on Gathr documentation, please email us!