Generative AI in Gathr
Generative AI works by using advanced machine learning models, particularly neural networks, to generate new content based on patterns and data it has been trained on.
Gathr’s GenAI offerings can increase productivity, create unique experiences, innovate, and transform your business. Here’s a simplified breakdown of the process:

Leverage Generative AI-powered processors and industry-leading models in Gathr to build modern AI solutions for your data and use cases.
Use pre-packaged AI models for embeddings generation, Q & A, and summary generation.
Register AI models on MLflow tracking server, deploy and manage on Kubernetes with automated scripts, and run inferences in Gathr pipelines.
Vector DBs support - Redis, Milvus, and Pinecone vector databases for embedding-based operations.
GenAI Scope in Gathr
GenAI in the Gathr is a powerful tool for data processing and code generation, but it has certain boundaries that are important for users to understand. It operates only within its domain and avoids topics unrelated to the supported components.
No Access to External Data: The AI does not have access to external sources of real-time or historical data (for example, sports statistics, financial data, etc.).
No General Knowledge Queries: Queries related to general knowledge, such as geographical or historical facts, will not be answered. The assistant is designed specifically for data processing tasks within the platform.
Example: For Gathr’s SQL processor that offers GenAI support for writing SQL expressions using natural language, a user query which is not related to the provided dataset is responded as given below.
User Query: “What is Indian cricket team’s highest score?”
AI Response
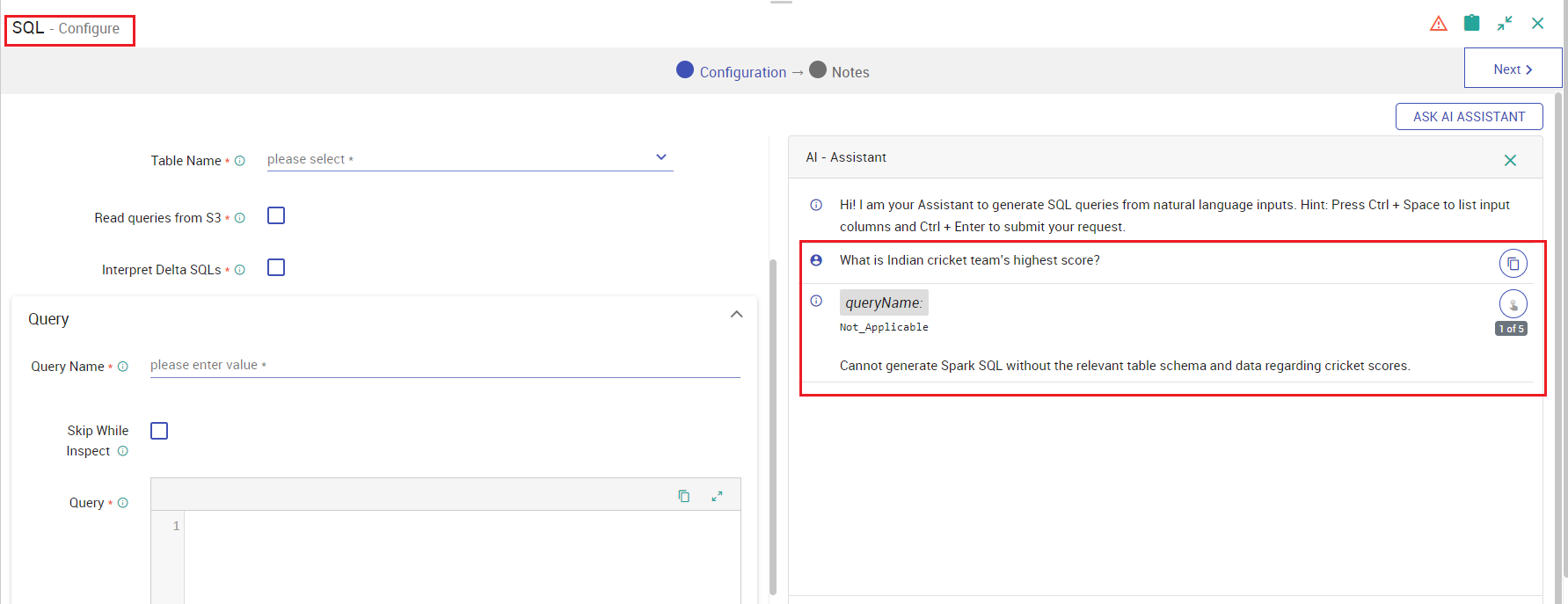
Similarly, other components offering GenAI assistance provide similar responses to unrelated queriers.
Data Parsing and Processing
Robust data parsing and processing capabilities with Binary-to-Text Parser and PDF Parser Processors.
The Binary-to-Text Parser converts binary data into readable text, making it easier to analyze and process.
The PDF Parser extracts text and data from PDF documents, enabling seamless integration of PDF content within your data workflows.
These processors enhance data accessibility and streamline processing tasks, making Gathr a powerful tool for handling diverse data formats.
Gen AI Models
Gathr’s GenAI Models feature powerful tools like the OpenAI Processor and OpenAI Embeddings.
The OpenAI Text processor leverages advanced AI models to perform a variety of natural language processing tasks, enhancing data analysis and automation.
The OpenAI Embeddings processor converts text into numerical vectors, enabling efficient semantic search, clustering, and classification.
These tools make it easier to understand and manipulate complex data, providing a robust foundation for innovative AI-driven solutions.
Gen AI Powered Processors
Gathr’s GenAI-powered processors include the Expression Evaluator, Expression Filter, Python, Scala, and SQL Processors, for data processing and analysis.
The Expression Evaluator performs various transformation operations on datasets using SparkSQL functions, such as formatting, trimming, and case conversion.
The Expression Filter allows for filtering datasets based on criteria like equality, ranges, and pattern matching.
The Python Processor enables custom Python code execution for data transformations and processing.
The Scala Processor supports custom Scala code for advanced data manipulation.
The SQL Processor allows for SQL-based data querying and transformation, leveraging the power of SQL within Gathr’s environment.
Generate code for these AI-powered processors using natural language instructions, making complex data tasks more accessible and intuitive.
MLflow in Gathr
MLflow is an open-source platform designed to manage the entire machine learning lifecycle. It helps streamline the process from experimentation to production deployment.
Integrating MLflow with Gathr allows you to connect your MLflow instance to Gathr’s interface. By setting up a connection to the MLflow Tracking Server, you can access and utilize your MLflow registered models directly within Gathr. This integration simplifies the process of employing MLflow models, making it easier to manage and deploy them effectively. Read more about MLflow integration within Gathr, here.
AI Models Supported by Gathr for MLflow Registration
The Gathr team can help register below models on your MLflow tracking server, enabling you to deploy them on Kubernetes using Gathr’s user interface. Once deployed, these models can be used in the model invoke processor within Gathr’s pipelines to run inferences.
| Type | Model Name | Quantized | Compute | Core/memory |
|---|---|---|---|---|
| Embedding | All-mpnet-base-v2 | No | gpu | [gpu, mem 2gb] |
| LLM Completion (summarization) | BART - philschmid/bart-large-cnn-samsum | No | gpu/cpu | [gpu mem 2gb]/[cpu, mem 3gb] |
| LLM Completion (text-generation) | Meta-Llama-3-8B-Instruct | Yes | Quantization Method - gptq | Architectures - LlamaForCausalLM gpu [gpu mem 8gb] |
Additionally, you can manually register any other models of your choice on the MLflow tracking server. Gathr provides support to register the listed models, making it easier to manage and deploy them effectively.
Third-Party Software
The third-party software required to leverage MLflow features in Gathr are listed below:
| Software | Version |
|---|---|
| MLflow Docker Bundle | 2.9.2 |
| Model Docker Image Bundle | (Official Base Image - Python:3.11.5-slim) |
| Redis Vector DB | 3.1.0 |
| Milvus Vector DB | 2.3 |
| Pinecone Vector DB | 4.0.0 |
On-Demand AI Models
These AI models are available on-demand to Gathr users.
Embeddings Generation:
all-mpnet-base-v2_embeddingSummary Generation:
bart-large-cnn-samsum_completionsText Generation:
Meta-Llama-3-8B-Instruct
Model Deployment and Usage
Gathr team will create a TAR bundle for these AI models upon request, package it, and share with user.
User runs the script provided by Gathr on MLflow to register the models on MLflow tracking.
User deploys model on Kubernetes through Gathr UI.
Models can now be used in Gathr pipelines with the Model Invoke processor.
Deployment and Configuration Scripts
All scripts are bundled together with MLflow and model-related packages.
See the Deployment and Configuration Scripts, here:
MLflow Server
Configure and start the MLflow tracking server on a specified port.
configure_mlflow.sh: Configures MLflow by editing the.envfile.deploy_mlflow.sh: Loads the MLflow Docker image and deploys it using Docker Compose. (Note: This process is offline.)
Model Registration
Users can either use the Gathr-provided scripts or register the models manually.
To register a model:
registerModels.sh bart-model-registrar: Registers the specified AI model provided by Gathr on the MLflow tracking server.registerModels.sh mpnet-model-registrar: Registers the specified AI model provided by Gathr on the MLflow tracking server.
Utility
Once the Model is Ready for Production:
configureloadTagPushImage.sh: To configure the.envfile for theloadTagPushImage.shscript. Set the following parameters:- IMAGE_TAR_PATH=/home/ec2-user/irisone.tar - IMAGE_NAME=irisone - IMAGE_TAG=latest - ENV1_PRIVATE_REPO_URL=172.26.78.4:5000 - ENV2_PRIVATE_REPO_URL=172.26.78.4:5000 - ENV2_REGISTRY_USERNAME=demoloadTagPushImage.sh: Loads the model Docker image from a tar file, tags it, logs in, and pushes the image to the production Docker registry (env 2).editAIGatewayConfig.sh: Opens theconfig.yamlfile for the AI Gateway.editFoundationModelJSON.sh: Opens theFoundationModelDetails.jsonfile for the AI model.
Hardware Preferences
System Requirements and Preferences
Gathr & MLflow Tracking Server:
Cores/RAM: 16 cores | 32 GB
Storage: 1 TB
OS: CentOS/RHEL 7.x/8.x
VM Node 1: Gathr, MLflow
GPU for ML Models:
GPU: NVIDIA (CUDA 12.2 or above)
Cores/RAM: Minimum 32 cores | 64 GB
VM Node 2: GPU-enabled K8 cluster
Additional Requirements
Docker: Must be installed on the Gathr node and have a Docker repository.
Kubernetes (K8) Cluster: Version 1.25.16 or higher. Ensure the cluster can access the GPU device. Follow the instructions for setup.
Deploy AI components
Models Supported by Gathr for MLflow Registration: Registered using the provided scripts on MLflow, and deployed via Gathr on an orchestration platform, like Kubernetes.
On-Demand Models: Registered by users on MLflow and deployed via Gathr on an orchestration platform, like Kubernetes
MLflow and Related Services:
Database: Gathr creates a new database to store MLflow metadata.
Webserver: MLflow Tracking Server.
Storage: Models are stored in S3 or NFS.
Deploy Gathr-Provided AI Models
Models are auto-registered in MLflow using provided scripts. The user deploys the models to Kubernetes from the Gathr UI.
Prerequisites: Docker installation, and environment configuration are required.
Deploy Additional Models:
Case 1: Request model bundle from Gathr and follow the deployment steps.
Case 2: If a user has registered their MLflow model, they can deploy it through Gathr for production use.
Remove Gathr Supplied Models
Users can delete models from Gathr’s MLflow Model’s listing page, which will also remove them from MLflow tracking.
Vector Lookup and Databases
Gathr supports advanced vector lookup and database operations with its integration of Redis, Milvus, and Pinecone vector databases.
Redis supports vector similarity search, making it ideal for real-time applications.
Milvus excels in handling large-scale vector data, providing robust and scalable solutions for AI and machine learning applications.
Pinecone offers a fully managed vector database service, simplifying the process of building and deploying high-performance vector search applications.
Deploy Vector DBs
Refer to Redis Stack Installation, Milvus Cluster Installation on Kubernetes, and Milvus Standalone Installation documentation for detailed steps.
If you have any feedback on Gathr documentation, please email us!