Emitters
Emitters define the destination stage of a pipeline which could be a NoSql store, Indexer, relational database, or third party BI tool.
CustomForeach is an action provided by Spark Structured Streaming. It provides a custom implementation for processing streaming data which is executed using the Foreach emitter.
Configuring CustomForeach Emitter for Spark Pipelines
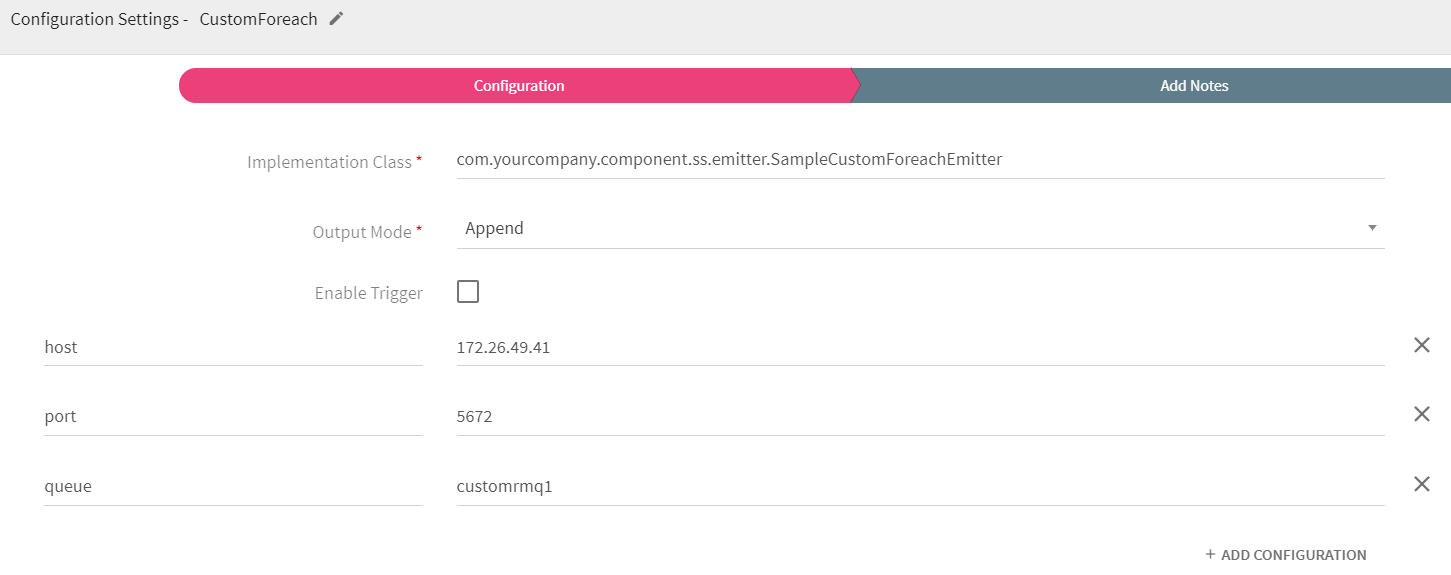
To add a CustomForeach into your pipeline, drag the CustomForeach to the canvas, connect it to a channel or processor, and right click on it to configure.
|
Field |
Description |
|---|---|
|
Implementation Class |
Foreach implementation class to which control will be passed in order to process incoming data flow. |
|
Output Mode |
Output mode to be used while writing the data to Streaming sink.
Select the output mode from the given three options:
Append Mode: This is the default mode, where only the new rows are added to the Result Table since the last trigger will be delivered to the sink. This is supported for only those queries where rows added to the Result Table are never going to change. Hence, this mode guarantees that each row will be output only once .
Complete: The whole Result Table will be delivered to the sink after every trigger. This is supported for aggregation queries.
Update: Only the rows in the Result Table that were sent since the last trigger will be delivered to the sink. |
|
Enable Trigger |
Trigger defines how frequently a streaming query should be executed. |
|
Processing Time |
It will appear only when Enable Trigger checkbox is selected. Processing Time is the trigger time interval in minutes or seconds. |
|
ADD CONFIGURATION |
Additional properties can be added using ADD CONFIGURATION link. |
Click on the Next button. Enter the notes in the space provided.
Click on the SAVE button for saving the configuration.
ElasticSearch emitter allows you to store data in ElasticSearch indexes.
While configuring an Elasticsearch emitter, you have to specify the target index name using a javascript expression and enable replication, shards, full text search and custom routing.
Configuring ElasticSearch Emitter for Spark Pipelines
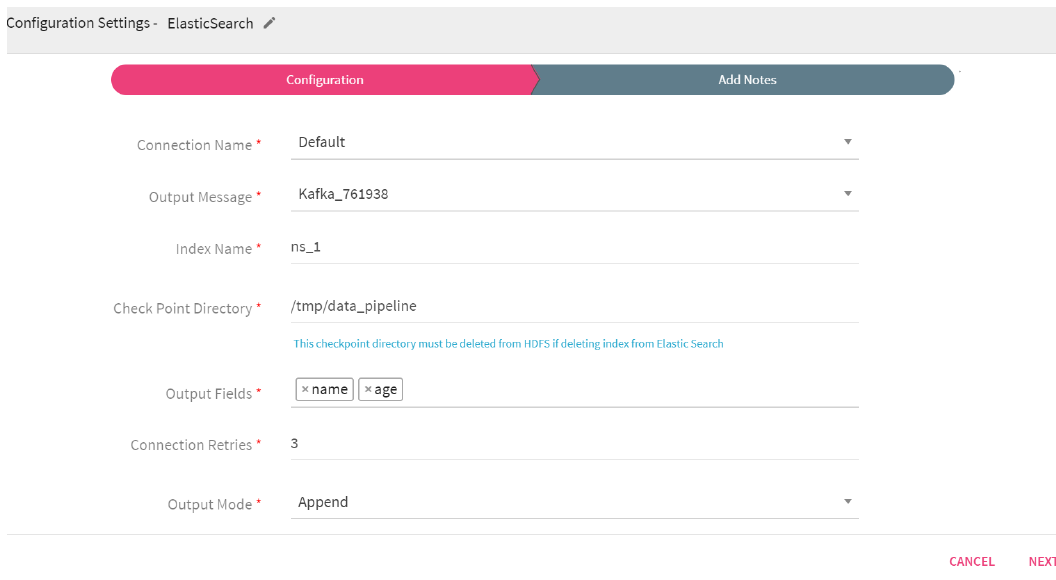
To add an Elastic Search emitter into your pipeline, drag the emitter to the canvas and connect it to a channel or processor. The configuration settings are as follows:
|
Field |
Description |
|---|---|
|
Connection Name |
All ElasticSearch connections will be listed here.Select a connection for connecting to ElasticSearch. |
|
Output Message |
Output message which is to be indexed. |
|
Index Name |
Specify the index name where data is to be indexed. |
|
Check Point Directory |
HDFS Path where the Spark application stores the checkpoint data. |
|
Output Fields |
Output message fields. |
|
Connection Retries |
Number of retries for component connection. Possible values are -1, 0 or positive number. -1 denotes infinite retries. |
|
Output Mode |
Output mode to be used while writing the data to Streaming sink.
Select the output mode from the given three options:
Append Mode: This is the default mode, where only the new rows are added to the Result Table since the last trigger will be delivered to the sink. This is supported for only those queries where rows added to the Result Table are never going to change. Hence, this mode guarantees that each row will be output only once .
Complete: The whole Result Table will be delivered to the sink after every trigger. This is supported for aggregation queries.
Update: Only the rows in the Result Table that were sent since the last trigger will be delivered to the sink |
|
Enable Trigger |
Trigger defines how frequently a streaming query should be executed. |
|
Processing Time |
It will appear only when Enable Trigger checkbox is selected. Processing Time is the trigger time interval in minutes or seconds. |
|
ADD CONFIGURATION |
Enables to configure additional ElasticSearch properties. |
Click on the Next button. Enter the notes in the space provided.
Click on the SAVE button for saving the configuration.
HBase emitter stores streaming data into HBase. It provides quick random access to huge amount of structured data.
Configure Hbase Emitter for Spark Pipelines
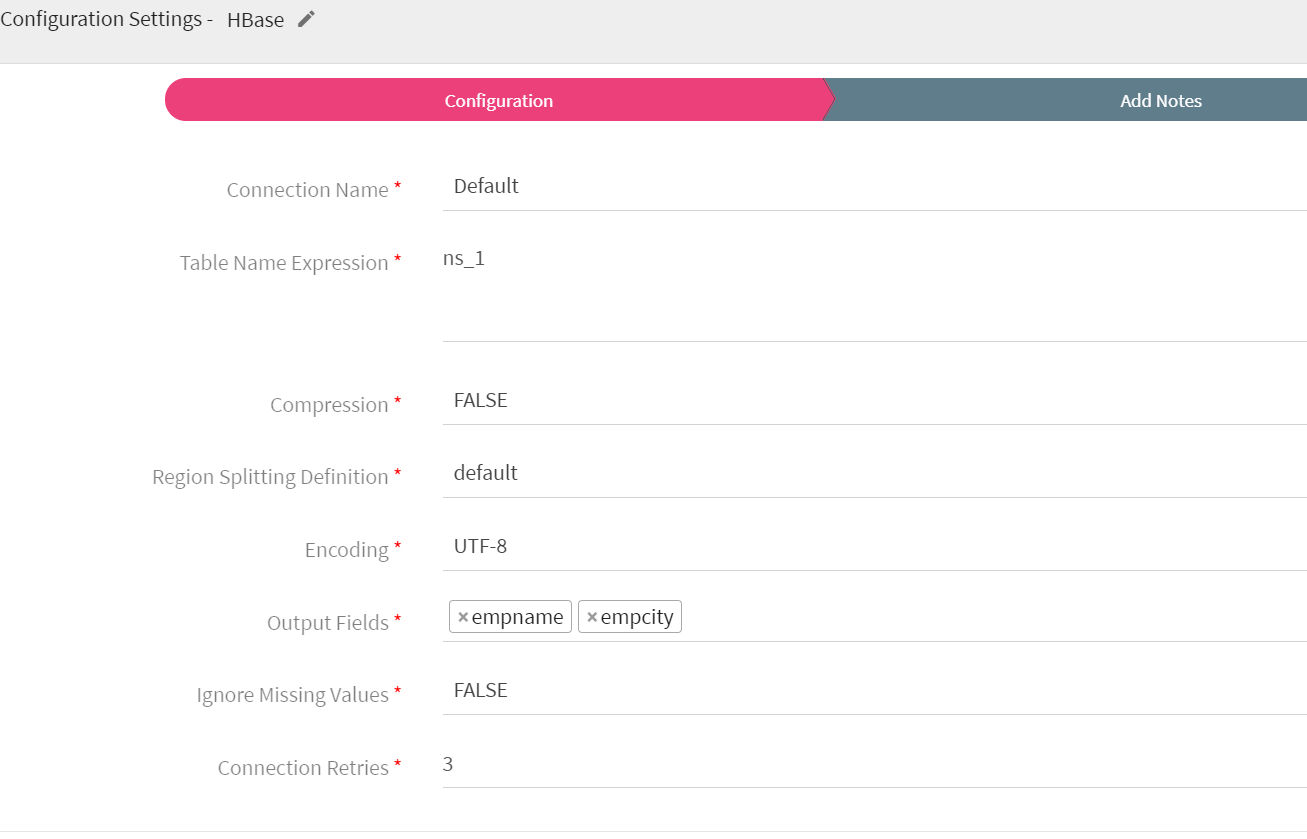
To add Hbase emitter to your pipeline, drag it to the canvas, connect it to a channel or processor, and right click on it to configure.
|
Field |
Description |
|---|---|
|
Connection Name |
All HBase connections will be listed here.Select a connection for connecting to HBase. |
|
Table Name Expression |
Javascript expression used to evaluate table name. The keyspace will be formed as ns_+{tenanatId} . For example, ns_1 |
|
Compression |
Provides the facility to compress the message before storing it. The algorithm used is Snappy. when selected true, enables compression on data |
|
Region Splitting Definition |
This functionality defines how the HBase tables should be pre-split. The default value is ‘No pre-split’. The supported options are: Default: No Pre-Split- Only one region will be created initially. Based on Region Boundaries: Regions are created based on given key boundaries. For example, if your key is a hexadecimal key and you provide a value ‘4, 8, d’, it will create four regions as follows:
1st region for keys less than 4
2nd region for keys greater than 4 and less than 8
3rd region for keys greater than 8 and less than d
4th region for keys greater than d |
|
Encoding |
Data encoding type either UTF-8 (base encoding) or BASE 64(64 bit encoding). |
|
Output Fields |
Fields in the message that needs to be a part of the output message. |
|
Ignore Missing Values |
Ignore or persist empty or null values of message fields in emitter. when selected true, ignores null value of message fields. |
|
Connection Retries |
The number of retries for component connection. Possible values are -1, 0 or positive number. -1 denotes infinite retries |
|
Delay Between Connection Retries |
Defines the retry delay intervals for component connection in millis. |
|
Enable TTL |
Specifies the life time of a record.when selected, record will persist for that time duration which you specify in TTL field text box. |
|
TTL Value |
Provide TTL value in seconds. |
|
Output Mode |
Output mode to be used while writing the data to Streaming sink.
Select the output mode from the given three options:
Append Mode: This is the default mode, where only the new rows are added to the Result Table since the last trigger will be delivered to the sink. This is supported for only those queries where rows added to the Result Table are never going to change. Hence, this mode guarantees that each row will be output only once.
Complete: The whole Result Table will be delivered to the sink after every trigger. This is supported for aggregation queries.
Update: Only the rows in the Result Table that were sent since the last trigger will be delivered to the sink. |
|
Enable Trigger |
Trigger defines how frequently a streaming query should be executed. |
|
Processing Time |
It will appear only when Enable Trigger checkbox is selected. Processing Time is the trigger time interval in minutes or seconds. |
|
ADD CONFIGURATION |
Enables to configure additional properties. |
Click on the Next button. Enter the notes in the space provided.
Click on the SAVE button for saving the configuration.
Hive emitter allows you to store streaming/batch data into HDFS. Hive queries can be implemented to retrieve the stored data.
To configure a Hive emitter, provide the database name, table name along with the list of fields of schema to be stored. This list of data rows get stored in Hive table, in a specified format, inside the provided database.
You must have the necessary permissions for creating table partitions and then writing to partition tables.
Configuring Hive Emitter for Spark Pipelines
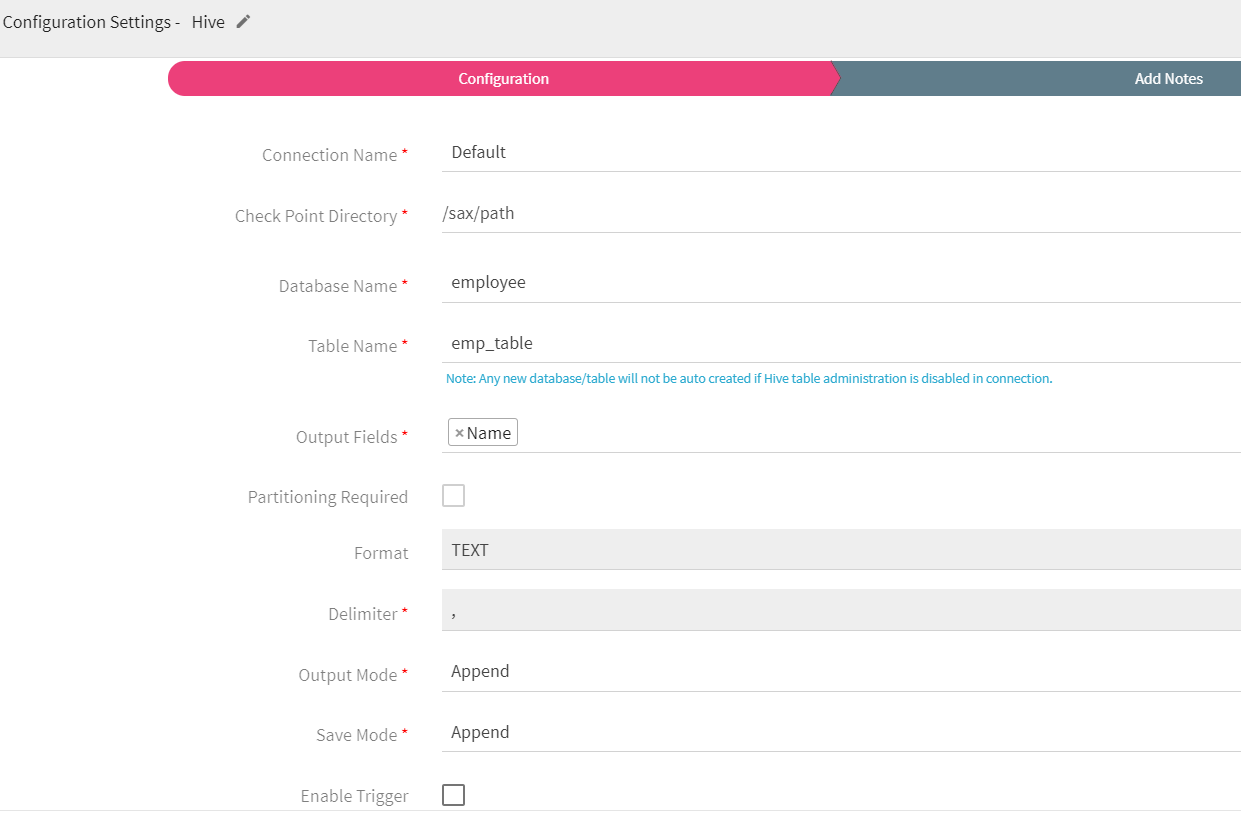
To add a Hive emitter into your pipeline, drag it to the canvas, connect it to a channel or processor, and right click on it to configure.
|
Field |
Description |
|---|---|
|
Connection Name |
All Hive connections will be listed here. Select a connection for connecting to Hive. |
|
Check Point Directory |
HDFS path where Spark application stores checkpoint data. |
|
Database Name |
HIVE database name. |
|
Table Name |
HIVE table name. |
|
Output Fields |
Fields in the schema that needs to be a part of the output data. |
|
Partitioning Required |
Check this option if HIVE table is to be partitioned. You will view Partition List input box. |
|
Format |
PARQUET: Columnar storage format and includes compression of file. TEXT: Stores information as plain text. |
|
Delimiter |
Message field separator |
|
Output Mode |
Output mode to be used while writing the data to Streaming sink.
Select the output mode from the given three options:
Append Mode: This is the default mode, where only the new rows are added to the Result Table since the last trigger will be delivered to the sink. This is supported for only those queries where rows added to the Result Table are never going to change. Hence, this mode guarantees that each row will be output only once.
Complete: The whole Result Table will be delivered to the sink after every trigger. This is supported for aggregation queries.
Update: Only the rows in the Result Table that were sent since the last trigger will be delivered to the sink. |
|
Save Mode |
Save operation specifies how to handle existing data if present.
ErrorifExist : When saving a DataFrame to a data source, if data already exists, an exception is expected to be thrown.
Append: When saving a DataFrame to a data source, if data/table already exists, contents of the DataFrame are expected to be appended to existing data.
Overwrite: Overwrite mode means that when saving a DataFrame to a data source, if data/table already exists, existing data is expected to be overwritten by the contents of the DataFrame.
Ignore: Ignore mode means that when saving a DataFrame to a data source, if data already exists, the save operation is expected to not save the contents of the DataFrame and to not change the existing data. This is similar to a CREATE TABLE IF NOT EXISTS in SQL. |
|
Enable Trigger |
Trigger defines how frequently a streaming query should be executed.g |
|
Processing Time |
It will appear only when Enable Trigger checkbox is selected. Processing Time is the trigger time interval in minutes or seconds. |
|
Add Configuration |
Enables to configure custom properties. |
Click on the Next button. Enter the notes in the space provided.
Click on the SAVE button after entering all the details.
JDBC Emitter allows you to push data to relational databases like MySQL, PostgreSQL, Oracle DB and MS-SQL.
Configuring JDBC Emitter for Spark pipelines
To add a JDBC emitter into your pipeline, drag the JDBC emitter on the canvas and connect it to a channel or processor. The Configuration Settings of the JDBC emitter are as follows:
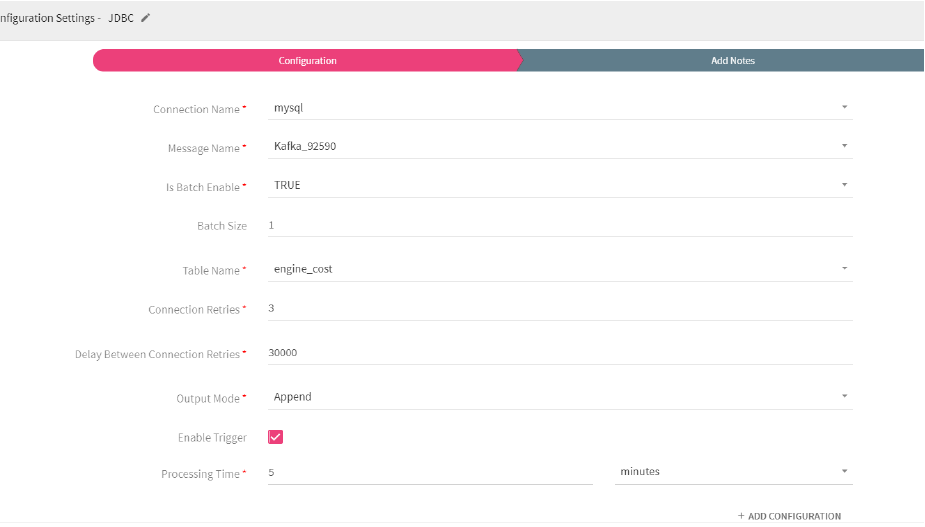
|
Field |
Description |
|---|---|
|
Connection Name |
All JDBC connections will be listed here. Select a connection for connecting to JDBC. |
|
Message Name |
Message used in the pipeline |
|
Is batch Enable |
Parameter used to batch multiple messages. |
|
batch Size |
Number of messages to be batched together. |
|
Table Name |
Existing database tablename whose schema is to be fetched. |
|
Connection Retries |
Number of retries for component connection |
|
Delay Between Connection Retries |
Defines the retry delay intervals for component connection in millis. |
|
Output Mode |
Output mode to be used while writing the data to Streaming emitter.
Select the output mode from the given three options:
Append Mode: This is the default mode, where only the new rows are added to the Result Table since the last trigger will be delivered to the sink. This is supported for only those queries where rows added to the Result Table are never going to change. Hence, this mode guarantees that each row will be output only once.
Complete: The whole Result Table will be delivered to the sink after every trigger. This is supported for aggregation queries.
Update: Only the rows in the Result Table that were sent since the last trigger will be delivered to the sink.
|
|
Enable Trigger |
Trigger defines how frequently a streaming query should be executed. |
|
Processing Time |
It will appear only when Enable Trigger checkbox is selected. Processing Time is the trigger time interval in minutes or seconds. |
|
ADD CONFIGURATION |
Enables to configure custom properties. |
Click on the NEXT button. Enter the notes in the space provided. Click SAVE for saving the configuration.
Kafka emitter stores data to Kafka cluster. Data format supported are JSON and DELIMITED.
Configuring Kafka Emitter for Spark Pipelines
To add a Kafka emitter into your pipeline, drag the Kafka emitter on the canvas and connect it to a channel or processor. The Configuration Settings of the Kafka emitter are as follows:
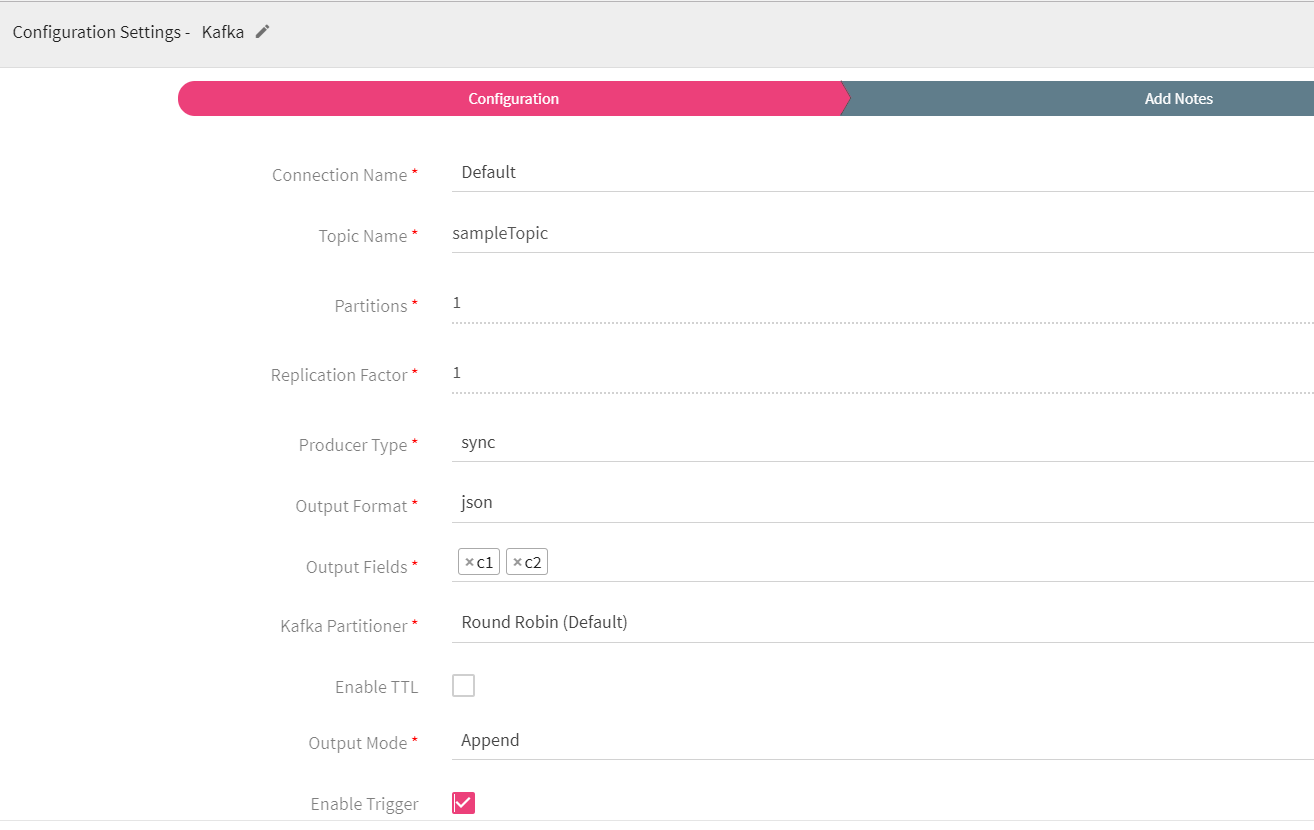
|
Field |
Description |
|---|---|
|
Connection Name |
All Kafka connections will be listed here.Select a connection for connecting to Kafka. |
|
Topic Name |
Kafka topic name where you want to emit data. |
|
Partitions |
Number of partitions to be created for a topic. Each partition is ordered, immutable sequence of messages that is continually appended to a commit log. |
|
Replication Factor |
For a topic with replication factor N, Kafka will tolerate up to N-1 failures without losing any messages committed to the log. |
|
Producer Type |
Specifies whether the messages are sent asynchronously or synchronously in a background thread. Valid Values are async for asynchronous send and sync for synchronous send |
|
Output Format |
Data type format of the output message. |
|
Output Fields |
Message fields which will be a part of output data. |
|
Kafka Partitioner |
Round Robin(Default): Kafka uses the default partition mechanism to distribute the data.
Key Based: kafka partitioning is done on the basis of keys.
Custom: Enables to write custom partition class by implementing the com.streamanalytix.framework.api.spark.partitioner.SAXKafkaPartitioner interface. The partition method contains logic to calculate the destination partition and returns the target partition number. |
|
Enable TTL |
Select the checkbox to enable TTL(Time to Live) for records to persist for that time duration. |
|
Output Mode |
Output mode to be used while writing the data to Streaming emitter.
Select the output mode from the given three options:
Append Mode: This is the default mode, where only the new rows are added to the Result Table since the last trigger will be delivered to the sink. This is supported for only those queries where rows added to the Result Table are never going to change. Hence, this mode guarantees that each row will be output only once .
Complete: The whole Result Table will be delivered to the sink after every trigger. This is supported for aggregation queries.
Update: Only the rows in the Result Table that were sent since the last trigger will be delivered to the sink. |
|
Enable Trigger |
Trigger defines how frequently a streaming query should be executed. |
|
Processing Time |
It will appear only when Enable Trigger checkbox is selected. Processing Time is the trigger time interval in minutes or seconds. |
Kinesis emitter emits data to Amazon Kinesis stream. Supported data type formats of the output are Json and Delimited.
Configure Kinesis Emitter for Spark Pipelines
To add a Kinesis emitter into your pipeline, drag the emitter on to the canvas, connect it to a channel or processor, and right click on it to configure it.
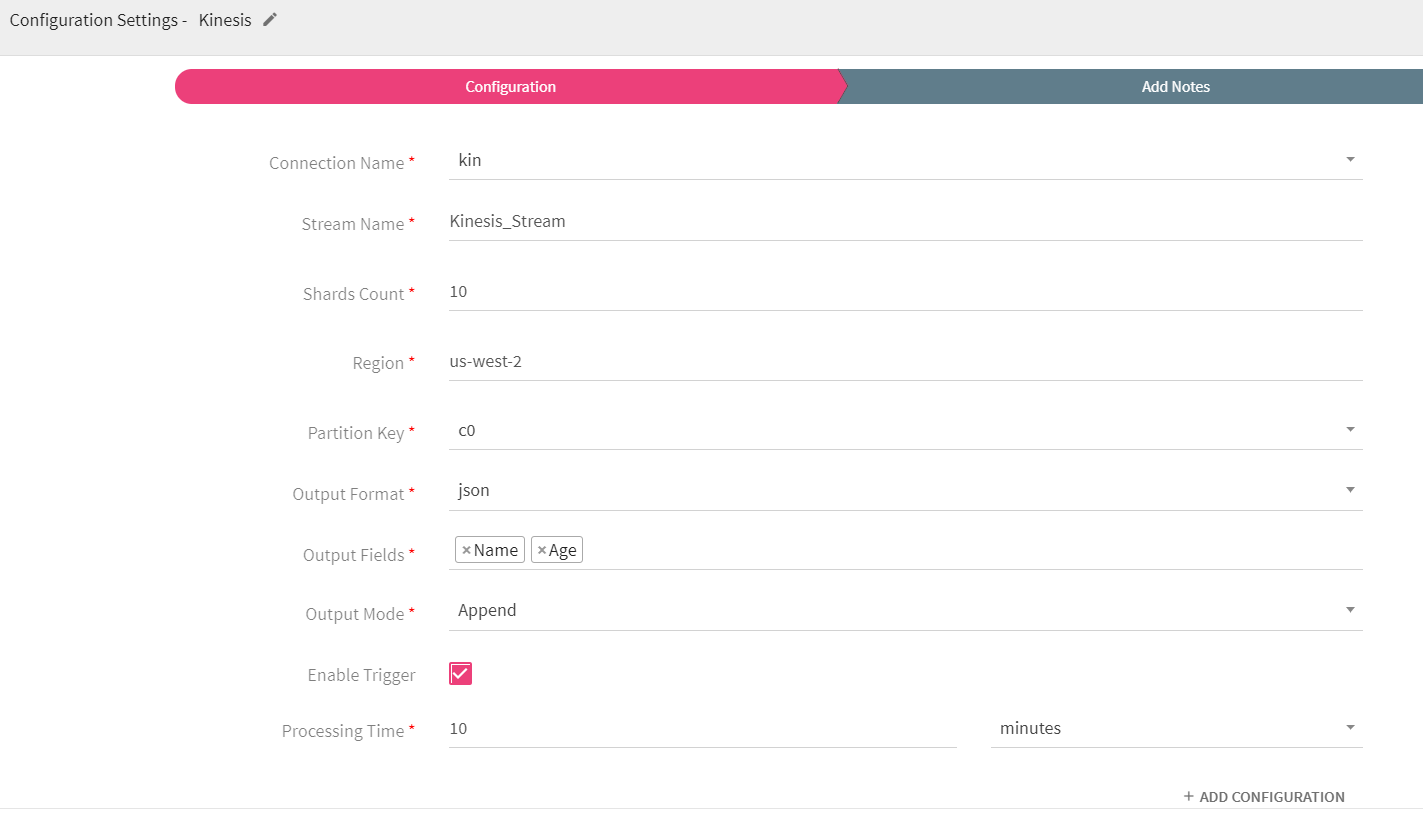
|
Field |
Description |
|---|---|
|
Connection Name |
All Kinesis connections will be listed here. Select a Kinesis connection for connecting to Kinesis. |
|
Stream Name |
Name of the Kinesis Stream. |
|
Shard Count |
Number of shards required to create the stream, in case stream is not present. |
|
Region |
Name of the region. For example, us-west-2 |
|
Partition Key |
Used by Amazon Kinesis to distribute data across shards. |
|
Output Format |
Datatype format of the output. |
|
Output Fields |
Fields in the message that needs to be a part of the output data. |
|
Output Mode |
Mode to be used while writing the data to Streaming sink.
Select the output mode from the given three options:
Append Mode: This is the default mode, where only the new rows are added to the Result Table since the last trigger will be delivered to the sink. This is supported for only those queries where rows added to the Result Table are never going to change. Hence, this mode guarantees that each row will be output only once.
Complete: The whole Result Table will be delivered to the sink after every trigger. This is supported for aggregation queries.
Update: Only the rows in the Result Table that were sent since the last trigger will be delivered to the sink. |
|
Enable Trigger |
Trigger defines how frequently a streaming query should be executed. |
|
Processing Time |
It will appear only when Enable Trigger checkbox is selected. Processing Time is the trigger time interval in minutes or seconds. |
|
ADD CONFIGURATION |
Enables to configure additional properties. |
Click on the Next button. Enter the notes in the space provided. Click Save for saving the configuration details.
Mqtt emitter emits data to Mqtt queue or topic. Supported output formats are Json, and Delimited.
Mqtt supports wireless network with varying levels of latency.
Configuring Mqtt Emitter for Spark Pipelines
To add Mqtt emitter into your pipeline, drag the emitter on to the canvas, connect it to a channel or processor, and right click on it to configure it.
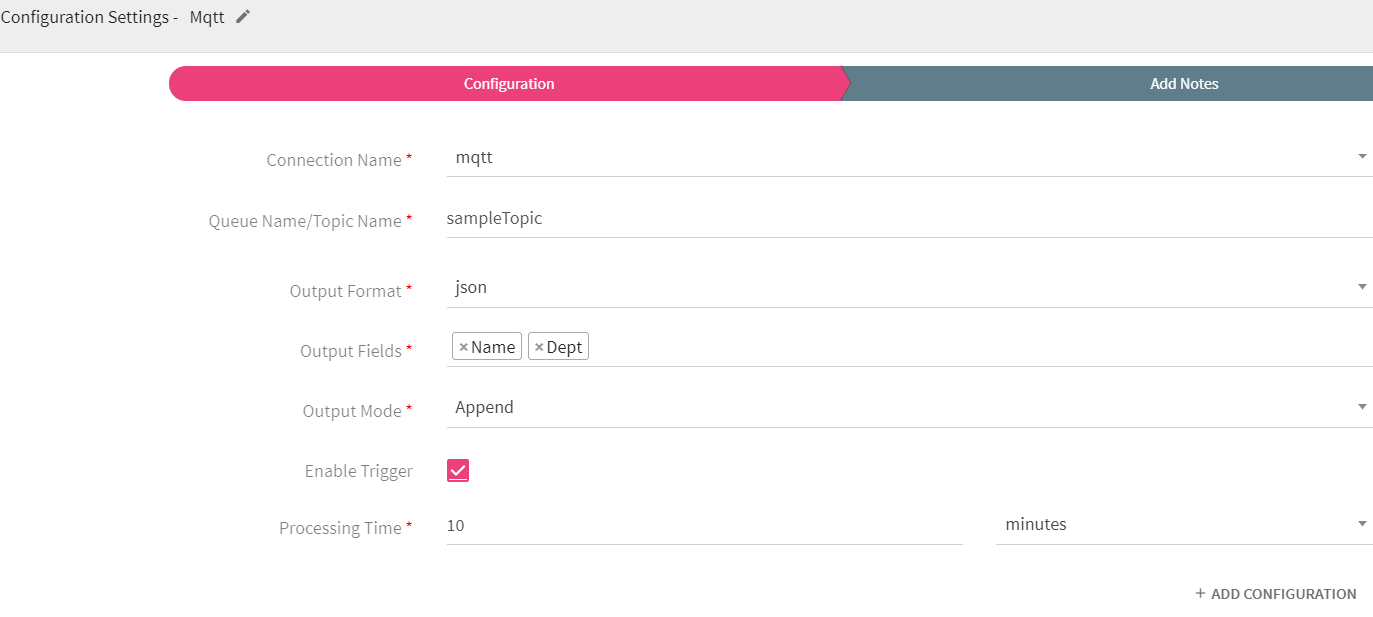
|
Field |
Description |
|---|---|
|
Connection Name |
All Mqtt connections will be listed here. Select a connection for connecting to Mqtt. |
|
Queue Name/Topic Name |
Queue or topic name to which messages will be published. |
|
Output Format |
Datatype format of the output. |
|
Output Fields |
Fields in the message that needs to be a part of the output data. |
|
Output Mode |
Output mode to be used while writing the data to Streaming sink.
Select the output mode from the given three options:
Append Mode: This is the default mode, where only the new rows are added to the Result Table since the last trigger will be delivered to the sink. This is supported for only those queries where rows added to the Result Table are never going to change. Hence, this mode guarantees that each row will be output only once .
Complete: The whole Result Table will be delivered to the sink after every trigger. This is supported for aggregation queries.
Update: Only the rows in the Result Table that were sent since the last trigger will be delivered to the sink |
|
Enable Trigger |
Trigger defines how frequently a streaming query should be executed. |
|
Processing Time |
Trigger time interval in minutes or seconds. |
|
ADD CONFIGURATION |
Enables to configure additional properties. |
Click on the Add Notes tab. Enter the notes in the space provided.
Click SAVE for saving the configuration.
HDFS emitter stores data in Hadoop Distributed File System.
To configure a Native HDFS emitter, provide the HDFS directory path along with the list of fields of schema to be written. These field values get stored in HDFS file(s), in a specified format, inside the provided HDFS directory.
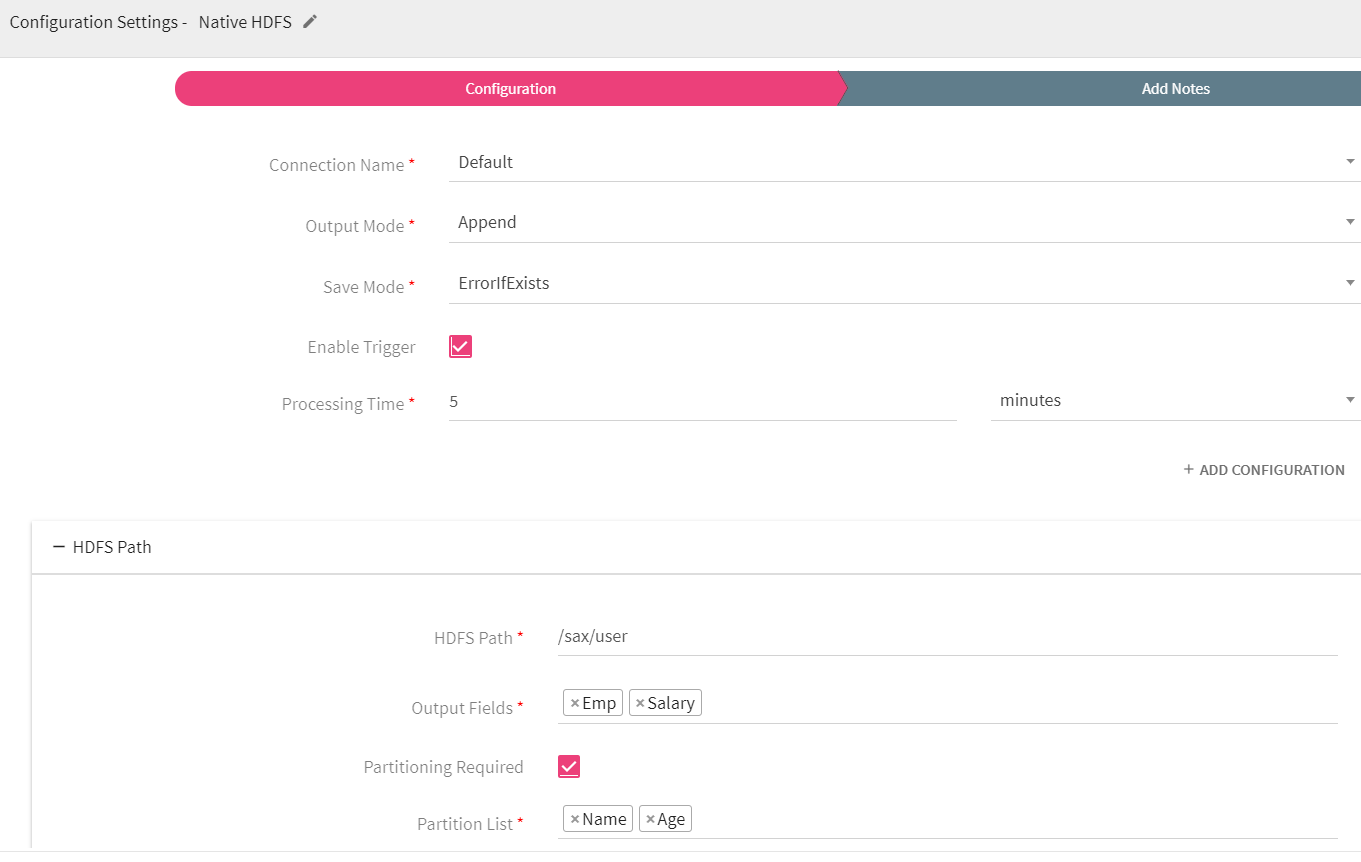
Configuring Native HDFS for Spark Pipelines
To add Native HDFS emitter into your pipeline, drag the emitter on to the canvas, connect it to a channel or processor, and right click on it to configure it.
|
Field |
Description |
|---|---|
|
Connection Name |
All Native HDFS connections will be listed here.Select a connection for connecting to HDFS. |
|
Output Mode |
Output mode to be used while writing the data to Streaming sink.
Select the output mode from the given three options:
Append Mode: This is the default mode, where only the new rows are added to the Result Table since the last trigger will be delivered to the sink. This is supported for only those queries where rows added to the Result Table are never going to change. Hence, this mode guarantees that each row will be output only once.
Complete: The whole Result Table will be delivered to the sink after every trigger. This is supported for aggregation queries.
Update: Only the rows in the Result Table that were sent since the last trigger will be delivered to the sink. |
|
Save Mode |
Save operation specifies how to handle existing data if present.
ErrorifExist : When saving a DataFrame to a data source, if data already exists, an exception is expected to be thrown.
Append: When saving a DataFrame to a data source, if data/table already exists, contents of the DataFrame are expected to be appended to existing data.
Overwrite: Overwrite mode means that when saving a DataFrame to a data source, if data/table already exists, existing data is expected to be overwritten by the contents of the DataFrame.
Ignore: Ignore mode means that when saving a DataFrame to a data source, if data already exists, the save operation is expected to not save the contents of the DataFrame and to not change the existing data. This is similar to a CREATE TABLE IF NOT EXISTS in SQL. |
|
Enable Trigger |
Trigger defines how frequently a streaming query should be executed. |
|
Processing Time |
Trigger time interval in minutes. |
|
HDFS Path |
Directory path on HDFS where data has to be written. |
|
Output Fields |
Fields which will be part of output data. |
|
Partitioning Required |
if checked, table will be partitioned. |
|
Partition List |
Select the fields on which table is to be partitioned. |
|
Output Type |
Output format of the request.Supported formats are CSV and JSON. |
|
Delimiter |
Delimiter character is used to separate two fields. |
|
Check Point Directory |
HDFS path where Spark application stores the checkpoint data. |
|
Block Size |
Size of each block(in Bytes) allocated in HDFS. |
|
Replication |
Enables to make additional copies of data. |
|
Compression Type |
Algorithm used to compress the data. |
|
ADD CONFIGURATION |
Enables to configure additional ElasticSearch properties. |
Click on the NEXT button. Enter the notes in the space provided. Click SAVE for saving the configuration details.
JMS is mainly used to send and receive message from one application to another.OpenJms emitter is used when you want to write data to JMS queue or topic.All applications which have subscribed to those topics/queues will be able to read that data.
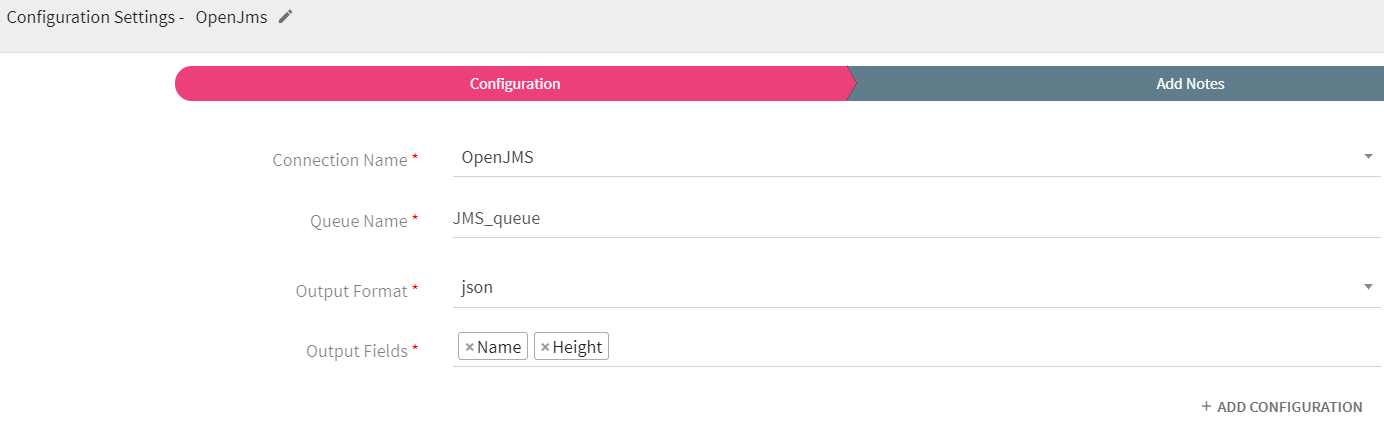
Configuring OpenJms Emitter for Spark Pipelines
To add OpenJms emitter into your pipeline, drag the emitter on to the canvas, connect it to a channel or processor, and right click on it to configure it.
|
Field |
Description |
|---|---|
|
Connection Name |
All OpenJms connections will be listed here.Select a connection for connecting to the OpenJMS. |
|
Queue Name |
Queue or topic name to which messages will be published. |
|
Output Format |
Select the data format in which OpenJMS should write the data. |
|
Output Fields |
Select the fields which should be a part of the output data. |
|
ADD CONFIGURATION |
Enables to configure additional properties. |
Click on the Next button. Enter the notes in the space provided.
Click SAVE for saving the configuration details.
The RabbitMQ emitter is used when you want to write data to RabbitMQ cluster.
Data formats supported are JSON and DELIMITED.
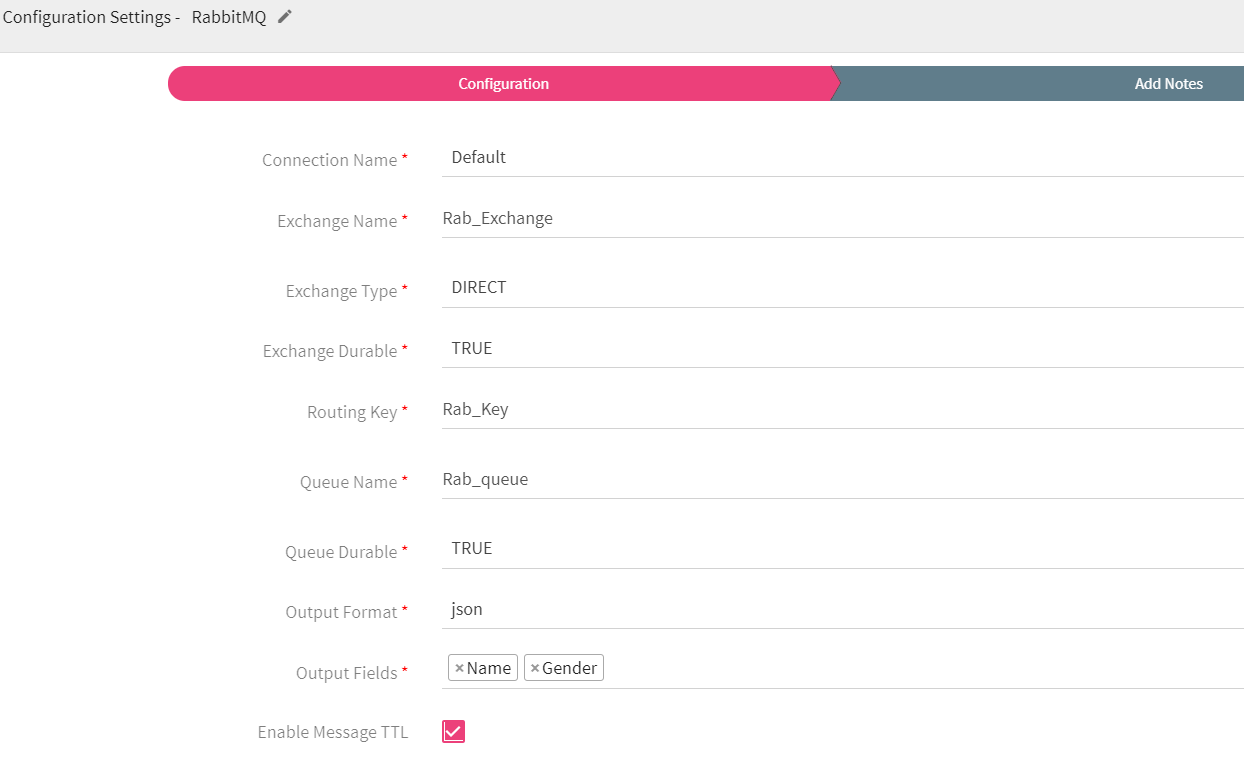
Configuring RabbitMQ Emitter for Spark Pipelines
To add a RabbitMQ emitter into your pipeline, drag the RabbitMQ emitter on the canvas and connect it to a channel or processor. Right click on the emitter to configure it as explained below:
|
Field |
Description |
|---|---|
|
Connection Name |
All RabbitMQ connections will be listed here.Select a connection for connecting to the RabbitMQ server. |
|
Exchange Name |
Rabbit MQ Exchange name |
|
Exchange Type |
Specifies how messages are routed through it .
Direct: Delivers message to queues based on a message routing key.
Fanout: Routes message to all of the queues that are bound to it.
Topic: Does a wildcard match between the routing key and the routing pattern specified in the binding. |
|
Exchange Durable |
Specifies whether exchange will be deleted or remain active on server restart.
TRUE: Exchange will not be deleted if you restart RabbitMQ server.
FALSE: Exchange will be deleted if you restart RabbitMQ server. |
|
Routing Key |
Select RabbitMQ routing Key where data will be published. |
|
Queue Name |
RabbitMQ queue name where data will be published. |
|
Queue Durable |
Specifies whether queue will remain active or deleted on server restart. TRUE: Queue will not be deleted if you restart RabbitMQ. FALSE: Queue will be deleted if you restart RabbitMQ. |
|
Output Format |
Select the data format in which RabbitMQ should write the data. |
|
Output Fields |
Select the fields which should be a part of the output data. |
|
Enable Message TTL |
when selected, message will be discarded to TTL exchange specified. |
|
Message TTL |
Time to live in seconds after which message will be discarded to TTL Exchange specified. |
|
TTL Exchange |
Exchange to which message will be sent once time to live expires. |
|
TTL Queue |
Queue on which message will be sent once time to live expires. |
|
TTL Routing Key |
Routing key used to bind TTL queue with TTL exchange. |
|
Output Mode |
Output mode to be used while writing the data to Streaming sink.
Select the output mode from the given three options:
Append Mode: This is the default mode, where only the new rows are added to the Result Table since the last trigger will be delivered to the sink. This is supported for only those queries where rows added to the Result Table are never going to change. Hence, this mode guarantees that each row will be output only once .
Complete: The whole Result Table will be delivered to the sink after every trigger. This is supported for aggregation queries.
Update: Only the rows in the Result Table that were sent since the last trigger will be delivered to the sink. |
|
Enable Trigger |
Trigger defines how frequently a streaming query should be executed. |
|
Processing Time |
Trigger time interval in minutes or seconds. |
|
Add Configuration |
Enables to configure additional RabbitMQ properties. |
Click on the NEXT button. Enter the notes in the space provided.Click SAVE for saving the configuration details.
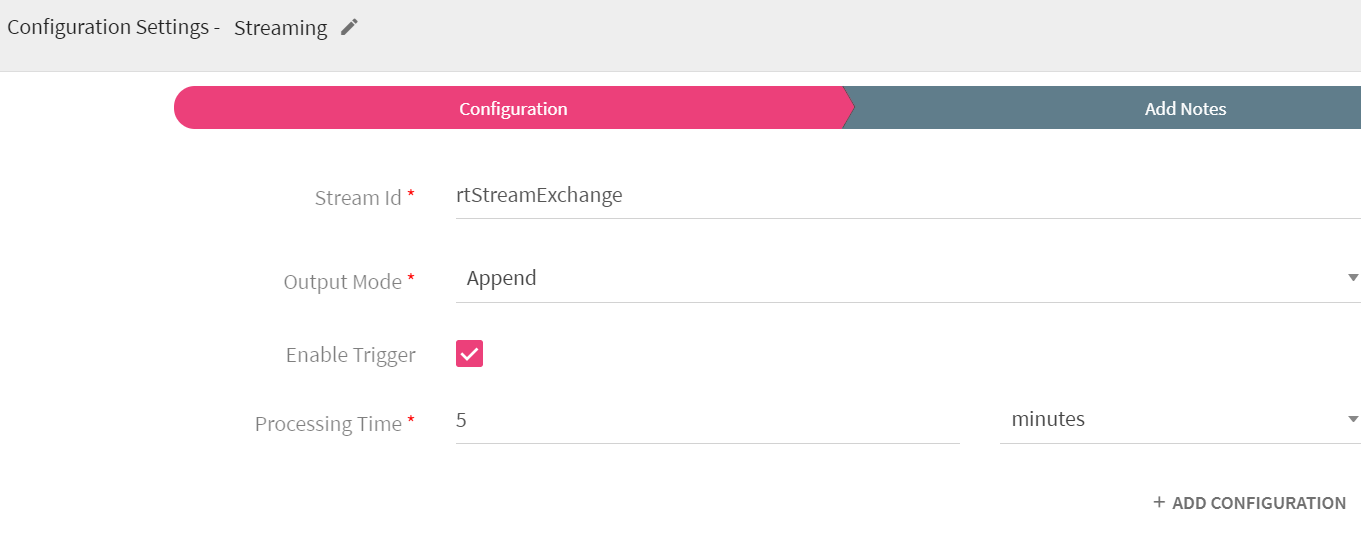
Streaming emitter enables you to visualize the data running in the pipeline in the StreamAnalytix built in real time dashboards. For example, you may use Streaming emitter to view real time price fluctuation of stocks.
|
Field |
Description |
|---|---|
|
Stream Id |
Exchange name on which streaming messages will be sent. |
|
Output Mode |
Output mode to be used while writing the data to Streaming sink.
Select the output mode from the given three options:
Append Mode: This is the default mode, where only the new rows are added to the Result Table since the last trigger will be delivered to the sink. This is supported for only those queries where rows added to the Result Table are never going to change. Hence, this mode guarantees that each row will be output only once .
Complete: The whole Result Table will be delivered to the sink after every trigger. This is supported for aggregation queries.
Update: Only the rows in the Result Table that were sent since the last trigger will be delivered to the sink |
|
Enable Trigger |
Trigger defines how frequently a streaming query should be executed. |
|
Processing Time |
Trigger time interval in minutes or seconds. |
|
ADD CONFIGURATION |
Enables to configure additional custom properties. |
Click on the Next button. Enter the notes in the space provided. Click Save for saving the configuration details.
Solr emitter allows you to store data in Solr indexes. Indexing is done to increase the speed and performance of search queries.
Configuring Solr Emitter for Spark Pipelines
To add a Solr emitter into your pipeline, drag it on the canvas and connect it to a channel or processor. The configuration settings of the Solr emitter are as follows:
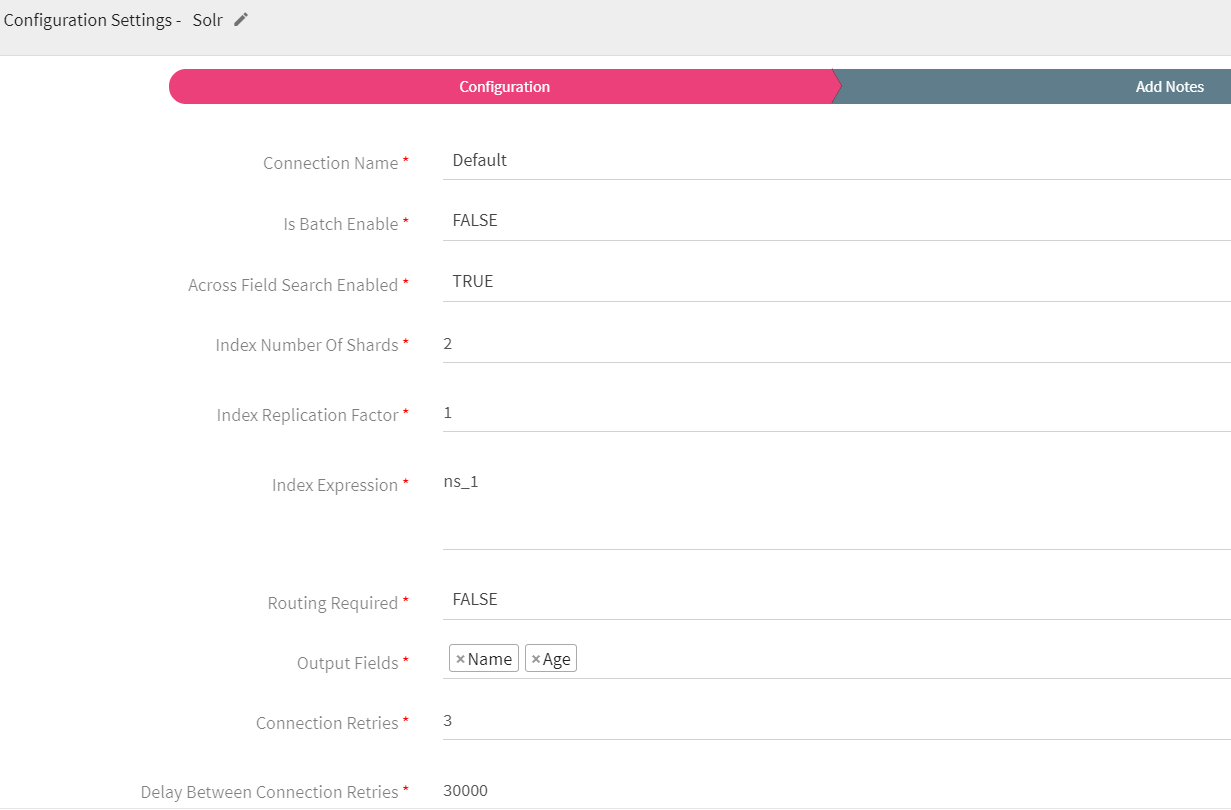
|
Field |
Description |
|---|---|
|
All Solr connections are listed here. Select a connection for connecting to Solr. |
|
|
Across Field Search Enabled |
Specifies if full text search is to be enabled across all fields. |
|
Index Number of Shards |
Specifies number of shards to be created in index store. |
|
Index Replication Factor |
Specifies number of additional copies of data to be kept across nodes. Should be less than n-1, where n is the number of nodes in the cluster. |
|
Index Expression |
The MVEL Expression is used to evaluate the index name. This can help you leverage field based partitioning.
For example consider the expression below:
@{'ns_1_myindex' + Math.round(<MessageName>.timestamp 3600*1000))}
Here a new index will be created with one-hour time range and data will be dynamically indexed based on field whose field alias name is 'timestamp'. |
|
Routing Required |
This specifies if custom dynamic routing is to be enabled. If enabled, a routing policy json needs to be defined as shown in the below figure. |
|
Output Fields |
Fields of the output message. |
|
Ignore Missing Values |
Ignore or persist empty or null values of message fields in emitter. |
|
Connection Retries |
Number of retries for component connection. Possible values are -1, 0 or positive number. -1 denotes infinite retries. If Routing Required =true, then:
Routing Policy - A json defining the custom routing policy. Example: {"1":{"company":{"Google":20.0,"Apple":80.0}}} where 1 is the timestamp after which custom routing policy will be active, 'company' is the field name and the value 'Google' takes 20% shards and value 'Apple' takes 80% shards. |
|
Delay Between Connection Retries |
Defines the retry delay intervals for component connection in millis. |