NVIDIA Models Listing Page
Manage and explore NVIDIA models by creating connections for NVIDIA services in Gathr.
To access this page, navigate through the Applications > Machine Learning > NVIDIA Tab.
Note: For models to display here, ensure at least one NVIDIA NIM or NVIDIA Triton connection has been created in Gathr.
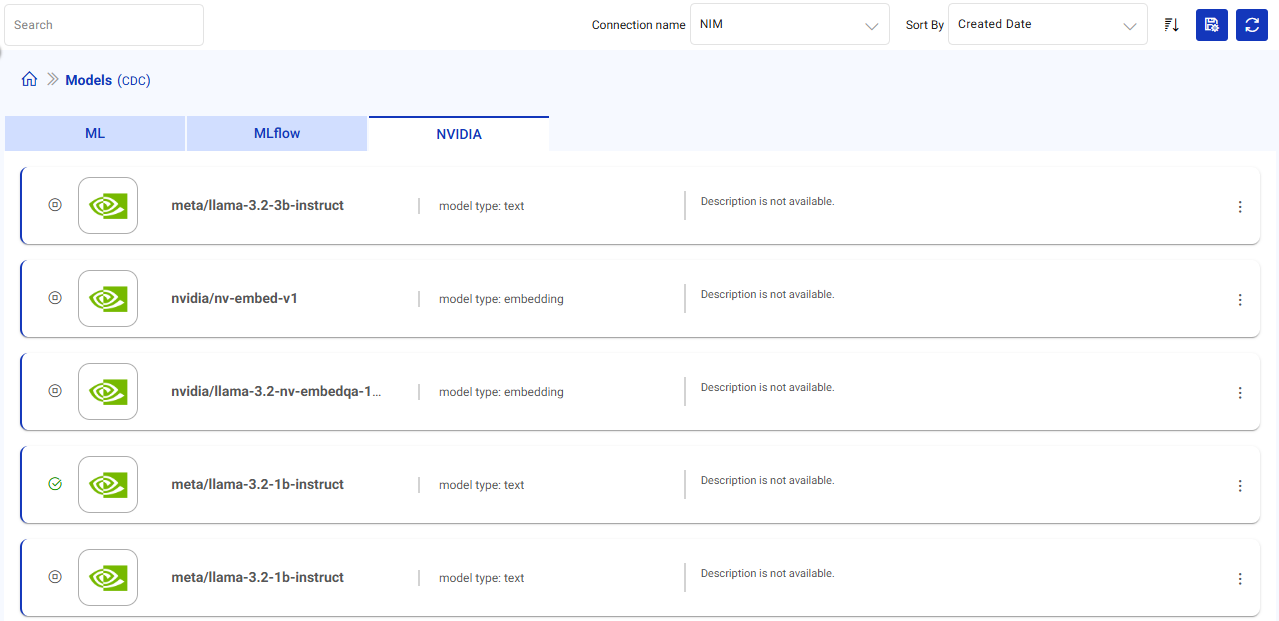
Upon selecting a connection, AI models associated with it will display. You can leverage these models within Gathr’s intuitive interface.
The actions available on the NVIDIA Models listing page are explained below:
Select a Connection: Choose from your configured connections to view models specific to that connection and manage the AI models.
Search: Enter the model names (case-sensitive) as keywords to quickly find models based on their names.
Sort Listed Models: Arrange models in ascending or descending order based on Model Names. In the Sort By field, select either ‘ASC’ (ascending) or ‘DEC’ (descending), and then click the ‘Sort’ button to list the models accordingly.
Display Number of Models per Page: Adjust the pagination settings to control how many models are displayed at once.
View Model Versions: Upon selecting a specific AI model from the listing, you can access detailed information and actions related to its versions. To know more, see View Model Versions.
The details shown on the NVIDIA Models listing page are:
Model Name: The unique identifier of the NVIDIA model.
Model Type: Categorization of the model (Example: sklearn, transformers).
Description: Optional user-provided information offering context or details about the model’s purpose and functionality.
View Model Versions
To explore model versions, click View Versions next to any model to access its detailed version listing page.
Here, you can view comprehensive information and perform various actions related to each version.
View Model Version Details
Dive deeper into the specifics of each version, including metadata, metrices, and various other details.
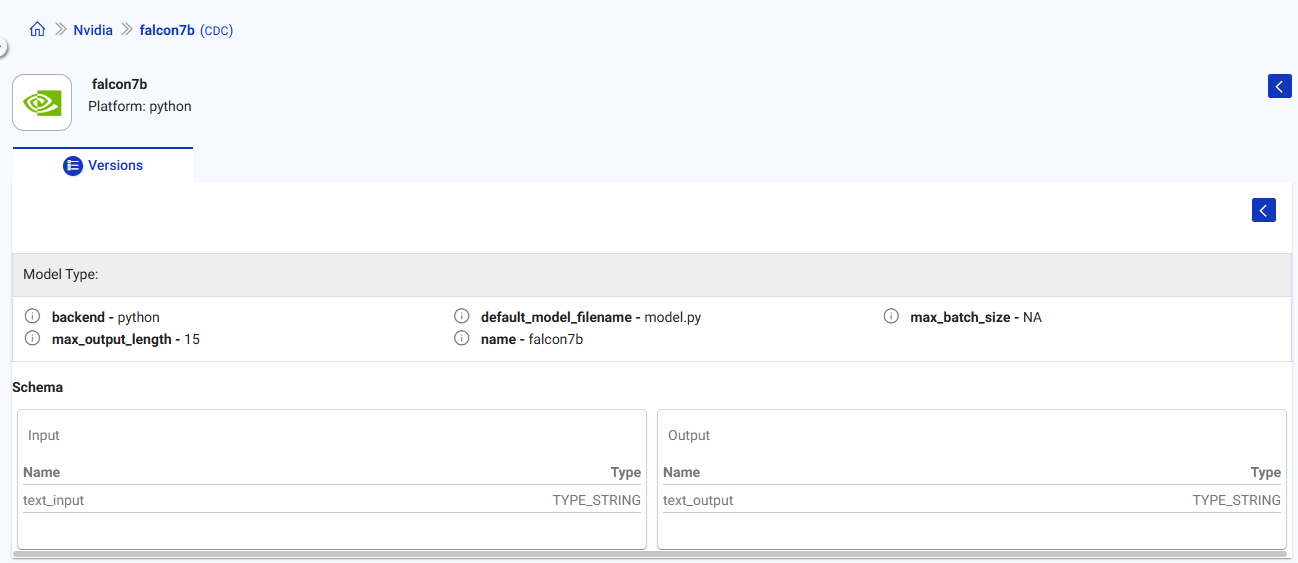
View Version
Under NVIDIA tab, click the View Versions option to see the version details.

The version, Endpoint URL (used to configure NVIDIA NIM Processor) and Status of the model deployment is available. The options to deploy the model and download it are available under Actions.

NVIDIA NIM Model Deployment Prerequisites
Before setting up and deploying NIM microservices, ensure the following prerequisites are met:
Infrastructure Requirements
Hardware
Kubernetes Cluster:
A Kubernetes cluster with NVIDIA GPU-enabled nodes.
A StorageClass must be configured in the Kubernetes cluster to dynamically provision persistent storage for NIM model weights.
Software
NVIDIA API Key:
An NGC API key from the NVIDIA GPU Cloud (NGC) is required to access NIM container images and the NVIDIA API Catalog for cloud-hosted models.
NVIDIA AI Enterprise License:
Required for deploying NIM microservices on-premises (not needed for cloud inference via NVIDIA API Catalog).
Obtainable through NVIDIA AI Enterprise subscription.
NVIDIA GPU Operator:
The NVIDIA GPU Operator must be installed on the Kubernetes cluster to manage GPU drivers, container runtimes, and CUDA libraries.
NVIDIA NIM Model Deployment Configurations
Cluster DNS
The DNS endpoint within the cluster where the NVIDIA NIM service will be deployed.
Namespace
Provide a cluster namespace where model is to be deployed to organize and manage resources.
Model App Name
Provide a name for the model to uniquely identify it within the cluster.
Tag
Provide the tag value for the model to be deployed.
Storage (GiB)
Allocate a storage space for the model image during execution. This parameter specifies the amount of storage (in Gigabytes or GiB) required for model images.
Storage class
Specify the storage class for the model storage speace.
NVIDIA GPU Cores
Provide the GPU cores to be used for model deployment.
Target Port
The port on which the model service will be exposed from the cluster. The port can range between 30000 - 32000. Ensure that the specified port is available.
Auto-Scaling Required
Select the check-box if auto-scaling is required. This option alows the automatic adjustment of the number of model instances based on resource utilization.
Instances
Provide minimum and maximum instances to scale the cluster.
Auto-Scale
Define the auto-scaling threshold (0.0 - 1.0), where 1.0 means full scaling capacity.
Send Email Notification
Select the check-box if email notifications are to be sent.
Email ID
Provide comma separated email id’s.
If you have any feedback on Gathr documentation, please email us!