Iceberg ETL Target
Iceberg is an open table format that brings database-like features to data lakes for managing large-scale datasets.
The Iceberg Emitter in Gathr allows data to be written to tables, supports schema evolution, and enables the creation of tables and schemas, as well as column addition and removal.
Provide the Catalog details for emitting data.
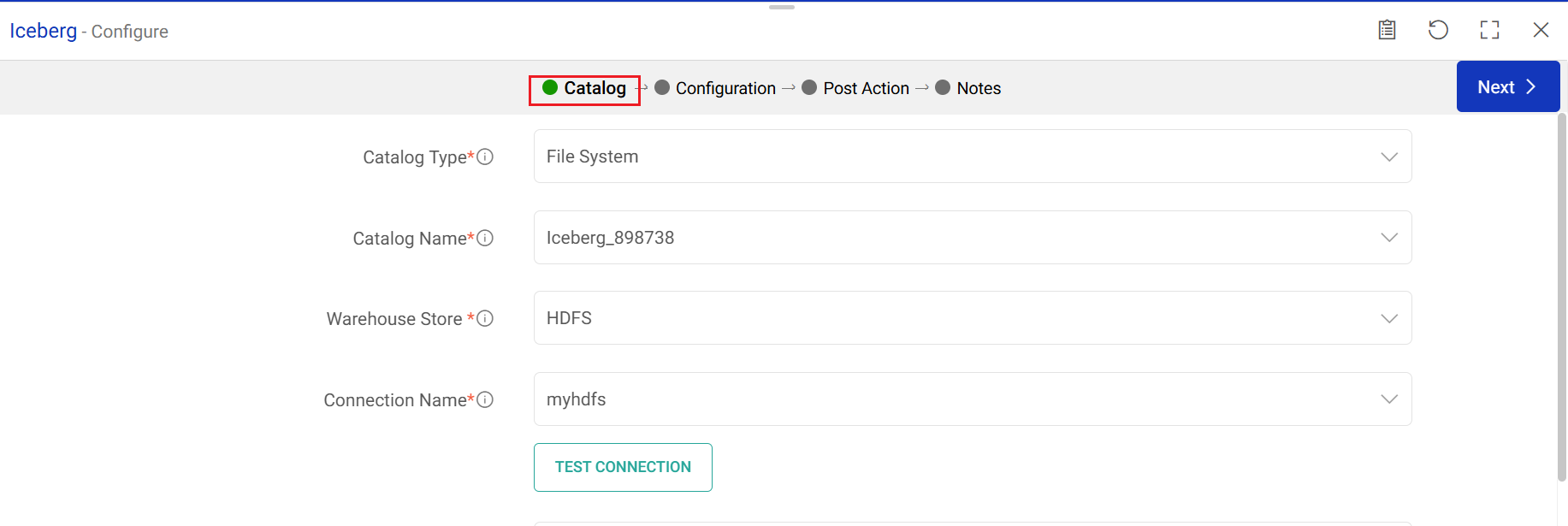
Catalog Type
Select the type of catalog from which the data is to be fetched.
Supported catalog types are: File System and JDBC.
File System
Read about File System Catalog Type Configurations here.
Catalog Name
A default catalog name generated by Gathr. It serves following purposes:
Gathr uses the table catalog to load Iceberg tables.
Warehouse Store
The warehouse storage system where data in Iceberg format is stored.
Supported systems are: S3, ADLS, and GCS.
Provide connection details for the chosen warehouse store.
Connect S3 Warehouse Store
Details required for connecting to S3 warehouse store.
Connection Name
Bucket Name
S3 Warehouse Path
Connection Name
Choose a connection name from the saved connections list or create a new one using the Add New Connection option.
Refer to topic S3 Connection for more details.
Bucket Name
Provide the bucket name.
S3 Warehouse Path
Based on the connection details, provide the directory path to access Iceberg data stored in S3.
Connect ADLS Warehouse Store
Details required for connecting to ADLS warehouse store.
Connection Name
Container Name
ADLS Warehouse Path
Connection Name
Choose a connection name from the saved connections list or create a new one using the Add New Connection option.
Refer to topic ADLS Connection for more details.
Container Name
Provide the container name.
Warehouse Path
Based on the connection details, provide the directory path to access Iceberg data stored in ADLS.
Connect GCS Warehouse Store
Details required for connecting to GCS warehouse store.
Connection Name
Bucket Name
GCS Warehouse Path
Connection Name
Choose a connection name from the saved connections list or create a new one using the Add New Connection option.
Refer to topic GCS Connection for more details.
Bucket Name
Provide the bucket name.
GCS Warehouse Path
Based on the connection details, provide the directory path to access Iceberg data stored in GCS.
JDBC
Read about JDBC Catalog Type Configurations here.
JDBC Connection
<div class="w-100">Iceberg supports <b>MySQL and Postgres</b> Databases. Make sure to provide a relevant connection. </div>
Choose a connection name from the saved connections list or create a new one using the ‘Add New Connection’ option.
Refer to topic JDBC Connection for more details.
Table Name
Select the Table Name iceberg_tables to list the Catalog Names.
Catalog Name
Select an existing Catalog name to load metadata from the JDBC metastore.
Warehouse Store
The warehouse storage system where data in Iceberg format is stored.
Supported systems are: S3, ADLS, and GCS.
Provide connection details for the chosen warehouse store.
Proceed further to provide configuration details.
Configuration
The configuration details are provided below.
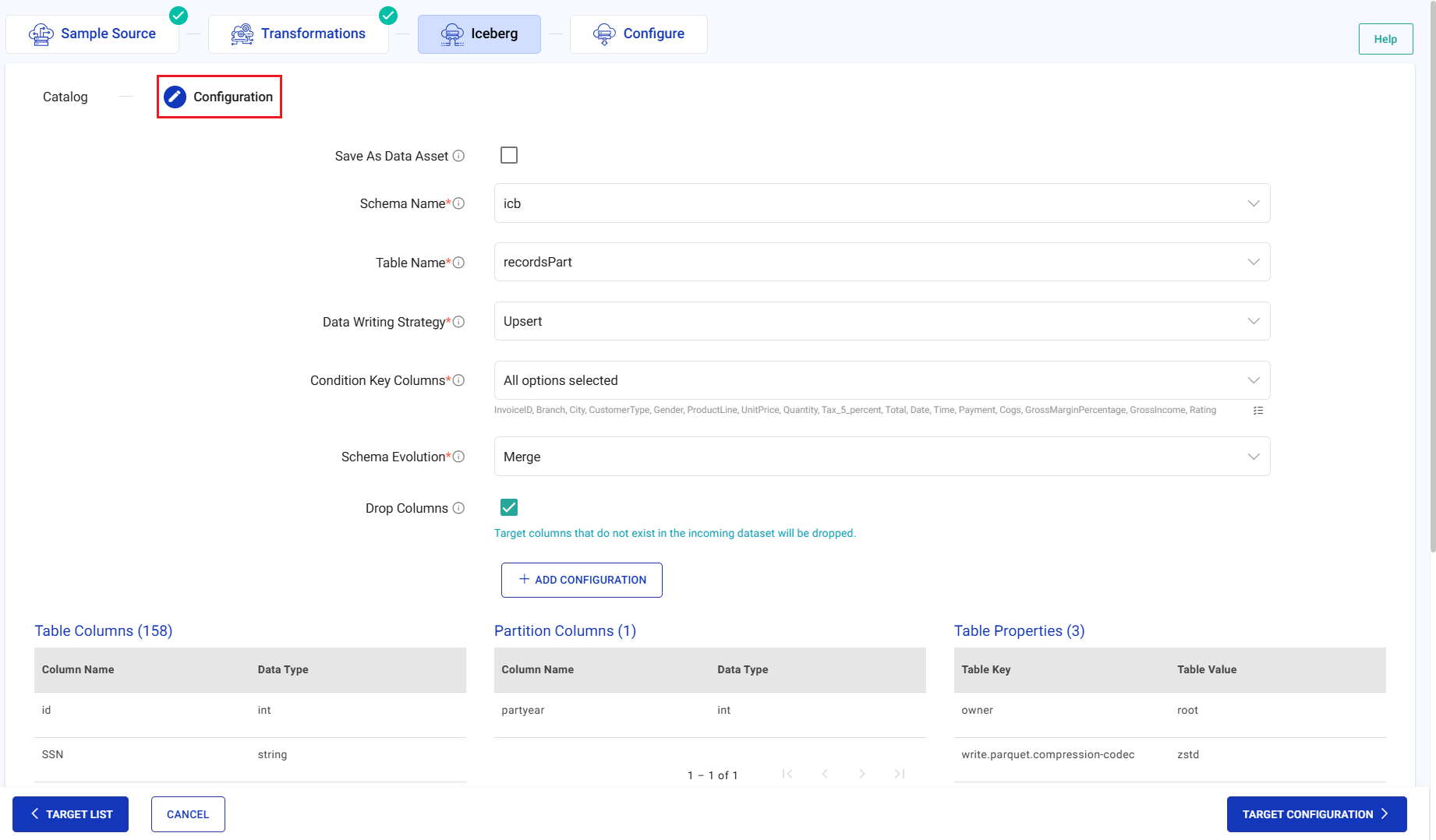
Save As Data Asset
Option to save the data of the component as Data Asset.
Scope
Select the scope of the data asset as either Global or Workspace.
Workspace
Select the workspace(s) to be included.
Data Asset Name
Provide name of the data asset.
Schema Name
Select the schema of the storage system that contains the Iceberg tables.
Table Name
Select the Iceberg table of the storage system where the data will be stored.
File Format
Select the file format in which the table data will be stored. Available options are: Parquet, AVRO and ORC.
Partition Table
Target tables will be created with partitions using the keys provided in partition columns.
Partition Columns
Select the column to create a partitioned table. These columns will be used as partition keys.
Data Writing Strategy
Specify how data should be written.
Append
Adds new data to the existing table.
Update
Modifies existing records based on key columns. The condition key column must be unique in the source data.
Upsert
Updates existing records and inserts new ones. The condition key column must be unique in the source data.
Upon selecting the Data Writing Strategy as Update/Upsert, provide the Condition Key Columns.
Condition Key Columns
Unique columns which need to be used as condition column as Update/Upsert mode.
Example: record_id, product_name, detailed_description
Schema Evolution
Controls how the incoming schema changes are handled in the target table.
The available options are: None and Merge.
None
Keeps the existing schema unchanged and ignores new fields.
Merge
Merge adds new fields to the target table schema.
Datatype updates are:
- int to bigint
- float to double
- decimal(P,S) to decimal(P2,S) when P2 > P (scale cannot change)
Drop Columns
Drop the target columns that do not exist in the incoming dataset.
Priority
Priority defines the execution order for the emitter.
ADD CONFIGURATION
Click to add further configurations as key-value pair.
Post Action
To understand how to provide SQL queries or Stored Procedures that will be executed during pipeline run, see Post-Actions →.
Notes
Optionally, enter notes in the Notes → tab and save the configuration.
If you have any feedback on Gathr documentation, please email us!